
Adaptive SM clocking for energy-efficient LLM serving
LLM serving is moving from occasional jobs to persistent service infrastructure. At that scale, GPU power is no longer a background detail. It sets thermal limi …
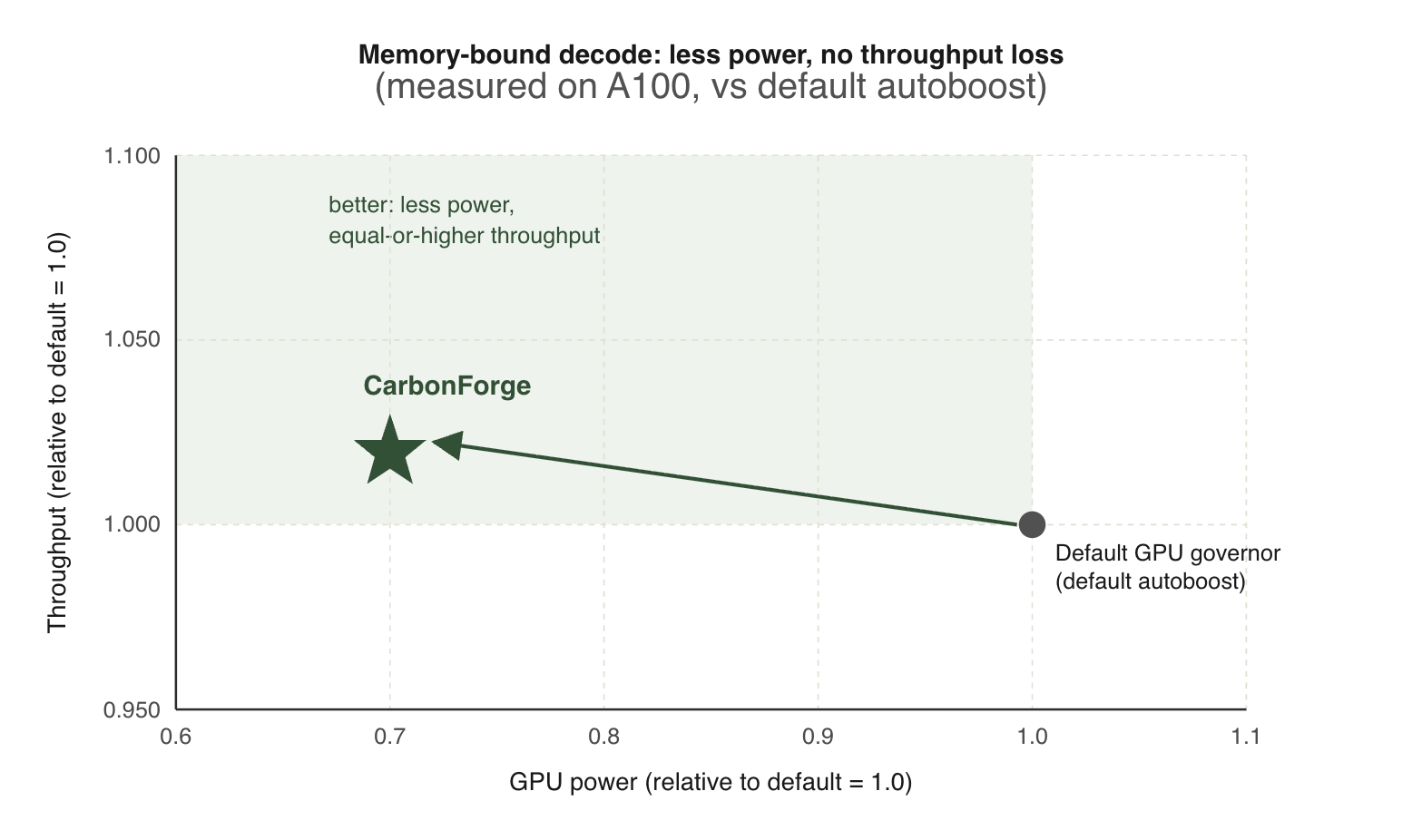
LLM serving is moving from occasional jobs to persistent service infrastructure. At that scale, GPU power is no longer a background detail. It sets thermal limi …